One of my favourite applications. I stopped paying for spotify and just use this to get music these days. Everything gets uploaded to youtube anyways.
this post was submitted on 25 Aug 2024
515 points (98.3% liked)
Open Source
31265 readers
253 users here now
All about open source! Feel free to ask questions, and share news, and interesting stuff!
Useful Links
- Open Source Initiative
- Free Software Foundation
- Electronic Frontier Foundation
- Software Freedom Conservancy
- It's FOSS
- Android FOSS Apps Megathread
Rules
- Posts must be relevant to the open source ideology
- No NSFW content
- No hate speech, bigotry, etc
Related Communities
Community icon from opensource.org, but we are not affiliated with them.
founded 5 years ago
MODERATORS
Downloading music from YouTube will get you MP3s, but they will have gone through the YT compression algorithms.
Use Deemix instead. Downloads MP3s straight from the Deezer servers with all metadata and album art.
Lucida.to would also be a pretty good choice, you can choose to download from either Deezer, Qobuz, Tidal, Spotify, Deezer or Amazon Music.
Does it automatically grab things like metadata (author, cover art, etc.) for you? And if it requires a flag, do you know it?
I don't bother personally for the most part but it seems like you can do it via --embed-metadata, --parse-metadata, and --embed-thumbnail.
Unless the artist only posts on YouTube, try soulseek. Most files have metadata already included, and if they don't, you can just download from another user.
load more comments
(1 replies)
It’s very automatic with just pointing it at the media’s URL, but also highly configurable if you want.
May I suggest SpotDL specifically for Spotify: https://github.com/spotDL/spotify-downloader
load more comments
(3 replies)
load more comments
(1 replies)
Absolutely. Bar none. Here's my config for downloading best quality YT videos (but works for other sites too) if anyone wants to base theirs on it: https://pastebin.com/ba9sFURT
Maybe a little bit shameless plug from me, but I want point to my Bash script for Linux to make the daily yt-dlp life easier: https://github.com/thingsiplay/yt-dlp-lemon yt-dlp-lemon -h will show only a few options and yt-dlp-lemon -H shows everything the script supports.
Oh hey i saw you in the comments of a brodie robertson video
Haha, hello there. World is small sometimes. :p
I wrote my own web app in Python, using pytube-fix and its lightning fast. Great library. I found a recent screenshot that's a bit behind in commits but you get the idea.
Edit: I published the source code, please note there is a LOT of work left to do, but it works. https://codeberg.org/ArtisanByteCrafter/pytube-gui
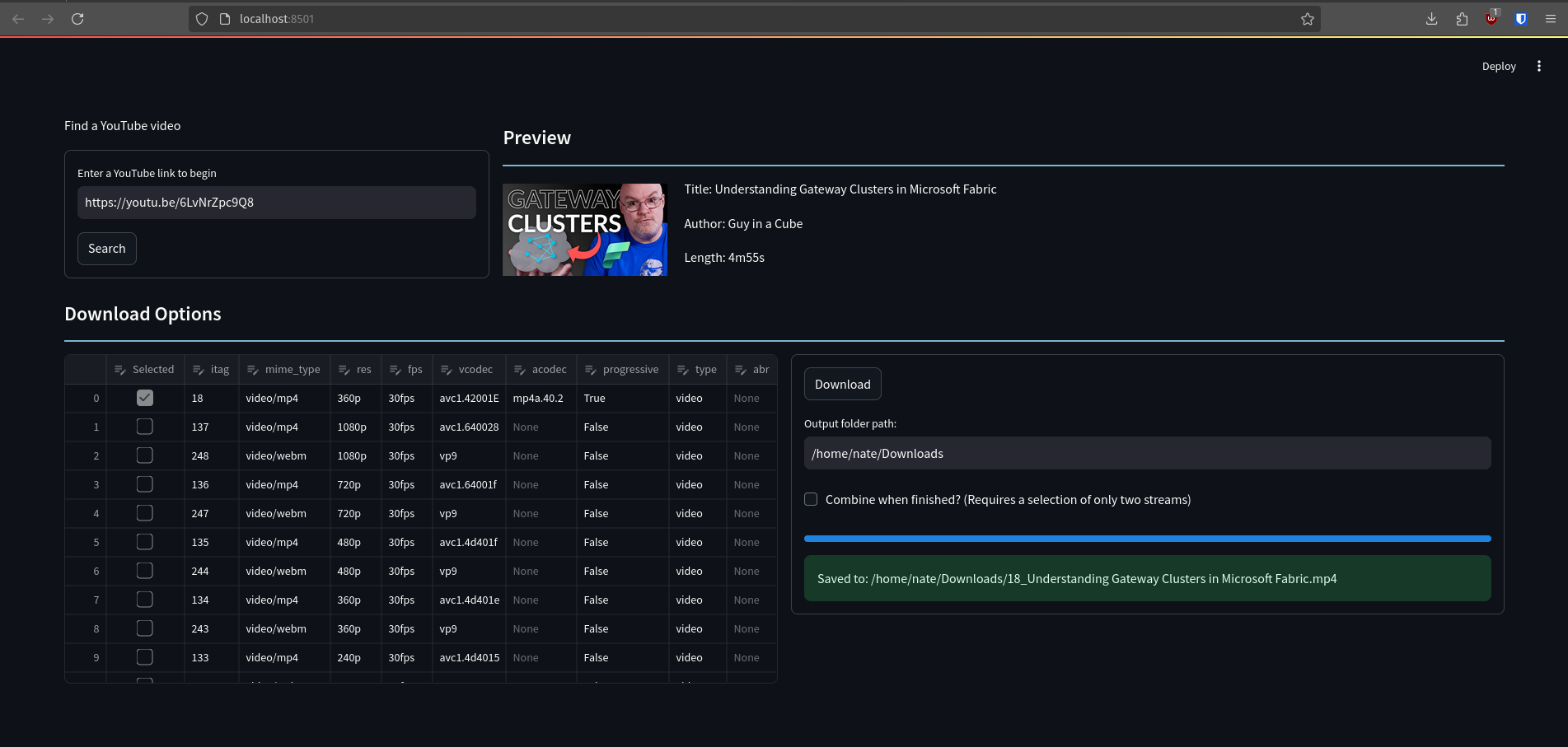
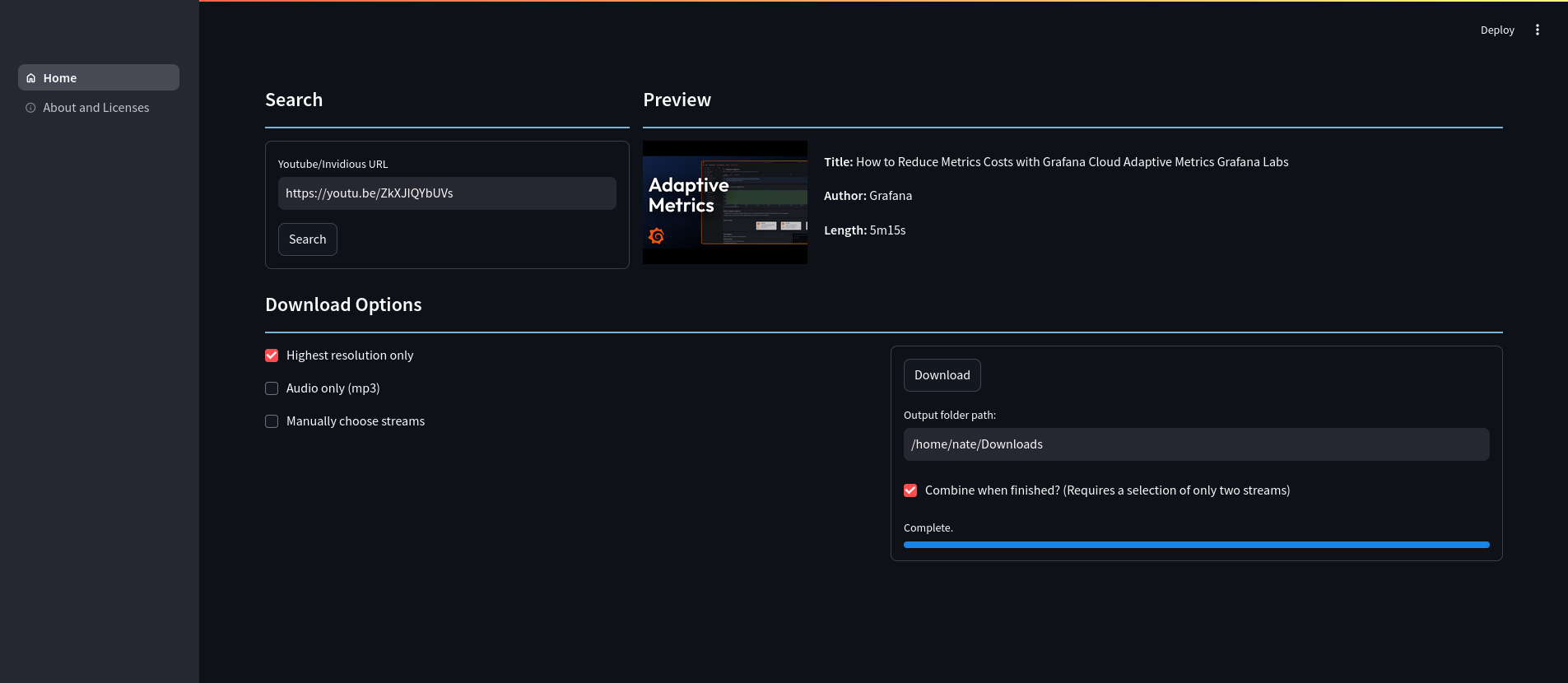
I didn't see anything like this image in the pytube-fix repo. Do you have a repo of the web interface somewhere? That looks really handy.
load more comments
(4 replies)
load more comments
(4 replies)
It's the main way I watch youtube now. After Piped and Newpipe stopped working for me across all devices, I only use 2 methods of watching Youtube now. Open in mpv (which is configured to use yt-dlp in the backend to make things faster), and download using yt-dlp. So it's key to me keeping on watching Youtube. Recently, I've started getting ads showing up even on Mobile Vivaldi, so no more YT on my phone.
So my new workflow is to use Piped to find a video, then copy the end of the link and type "yt-dlp " in a terminal, wait for the video(s) to download, and open in mpv.
OR
In some cases, use Qutebrowser, with a custom keybind to open a video in mpv.
load more comments
(23 replies)
yt-dlp is great, but if you need to archive playlists automatically, want a repository, or otherwise prefer a gui I would recommend TubeArchivist.
(Which itself uses yt-dlp)
load more comments
(1 replies)
I have been using Jdownloader2 for years.. I don’t know what the differences are, but might be an option for people who want something GUI based
If you need a gui or are trying to monitor playlists I would recommend TubeArchivist.
If you use it frequently, I suggest getting a GUI that have profiles or remember options so you don't have to mess with commands all the time. I wrote my own little command line wrspper which is Windows only since I don't have Linux to test on. Though it shouldn't take much effort to add support.
Makes it much more convenient when you don't have to specify things like archive (ignore duplicates), filename to be "artist - title" (where possible), download destination, etc. Just alt-tab, Ctrl-v, Enter. And the download is running. And mine also has parallel downloads and queue for when you got many slow downloads.
I tried a few times, but the video and audio are often out of sync. Anyone have this issue?
Strange. I downloaded thousands of videos with this tool (but just watched a handful of them) and never noticed an out of sync. Can you point me to a video I can download and test where you have this issue? Is it a new issue? Maybe Google is trolling us or you or your region.
load more comments
(4 replies)
No
load more comments
(1 replies)
I'll take anything with a GUI instead.
All of the good video downloaders are just a wrapper for using this, so it's not really "instead".
Does it work for movies that "require you to sign in to verify your age"?
This is wonderful, I've been struggling with piped for some time now, it's always asking me to sign in to confirm that I'm not a bot. Also it's showing me videos in very low quality and often it stops loading halfway through the video. With this I get to see good quality videos once more, without unwanted pauses and without financing yt in any way. Great!
I tried to download some videos from Reddit using YT-DLP and it didn't work, I think maybe because Reddit limited access
I made a script for grabbing reddit videos that's been working pretty well for me, needs Babashka to run https://babashka.org/
#!/usr/bin/env bb
(require '[clojure.java.shell :refer [sh]]
'[clojure.string :as string]
'[cheshire.core :as cheshire]
'[org.httpkit.client :as http]
'[clojure.walk :as walk])
(defn http-get [url]
(-> @(http/get url {})
:body))
(defn find-base-url [data]
(let [results (atom [])]
(walk/postwalk
(fn [node]
(when (and (string? node) (.contains node "DASH"))
(swap! results conj node))
node)
data)
(some-> @results first (string/replace #"DASH_[0-9]+\.mp4" ""))))
(defn find-best-quality [names audio?]
(->> ((if audio? filter remove) #(.contains (.toLowerCase %) "audio") names)
(sort-by
(fn [n]
(-> n
(string/replace #"\.mp4" "")
(string/replace #"[a-zA-Z_]" "")
(Integer/parseInt))))
(last)))
(defn find-parts [base-url data]
(let [url (atom nil)
_ (walk/prewalk
(fn [node]
(when (and (map? node)
(contains? node :dash_url))
(reset! url (:dash_url node)))
node)
data)
xml (http-get @url)
parts (->> (re-seq #"<BaseURL>(.*?)</BaseURL>" xml) (map second))
best-video (find-best-quality parts false)
best-audio (find-best-quality parts true)]
[(str base-url best-video) (str base-url best-audio)]))
(defn filename [url]
(let [idx (inc (.lastIndexOf url "/"))]
(subs url idx)))
(defn tsname []
(str "video-" (System/currentTimeMillis) ".mp4"))
(let [data (-> (first *command-line-args*) (str ".json") http-get (cheshire/decode true))
base-url (find-base-url data)
[video-url audio-url] (find-parts base-url data)
video-file (filename video-url)
audio-file (filename audio-url)]
(sh "wget" video-url)
(sh "wget" audio-url)
(sh "ffmpeg" "-i" video-file "-stream_loop" "-1" "-i" audio-file "-shortest" "-map" "0:v:0" "-map" "1:a:0" "-y" (tsname))
(sh "rm" audio-file video-file))
load more comments
(3 replies)
If you like this article, please consider following the site on Mastodon/Fedi, email, or RSS. It helps me get information like this out to a wider audience :)
load more comments
(2 replies)
view more: next ›