Thanks, corrected
mapto
joined 10 months ago
Thanks. I didn't know this and it is very useful information.
Even if so, your unreasonably pessimistic assumption is that this would be an exclusive source of revenue. Once content is created, cross-posting is free.
Thanks for doing the maths. Actually, it does show that there's a small, but unexploited market here. $2-3K a month is a very good income for the most of the world. And this doesn't have to be the only revenue stream.
Could you elaborate, please. I'm genuinely interested
Researching on time and place of arrival is a nice gift for anyone who wants to intercept these and is being cut off from doing this research themselves.
1
@kamilkazani on how a few Western corporations enable Russian arms manufacturing
(threadreaderapp.com)
To me it depends on the base image. Some don't have curl, but have wget. I would go with the flow instead of installing it myself. Especially if I can get away with not having to add more layers for an image of my own and/or using the same command for all containers
Ok, that was stupid. Doing healthcheck with wget, does what wget does: it downloads the result. I had to add --spider to stop doing that
wget -nv --spider http://localhost:8000 || exit 1Well, I do need OpenAPI (Swagger). What I don't need is the generation of thousands of equal static files. Out of all these generated files, index.html would've been enough and I don't need index.html.1, etc.
I deploy a FastAPI service with docker (see my docker-compose.yml and app).
My service directory gets filled with files index.html, index.html.1, index.html.2,... that all contain
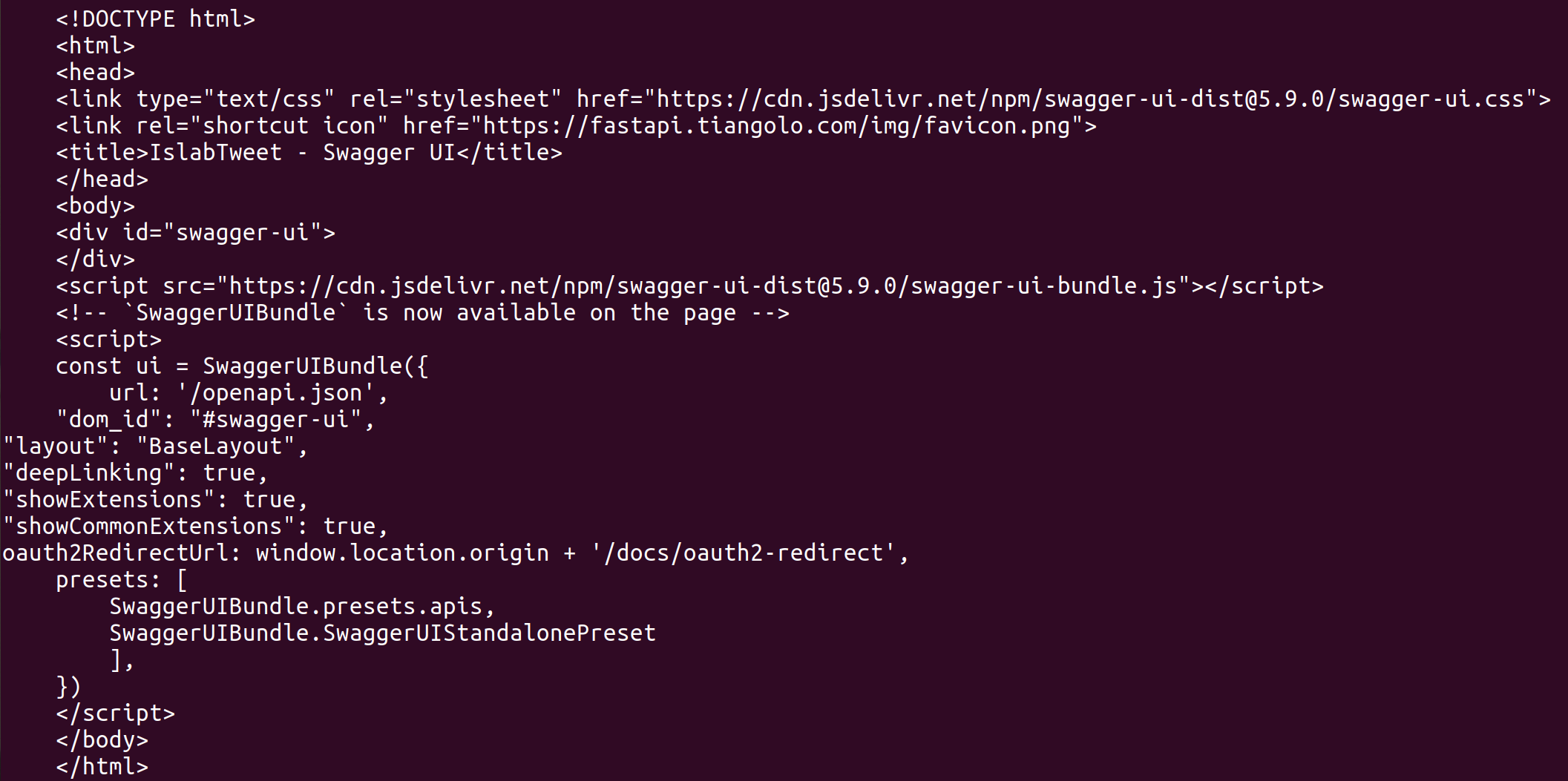
They seem to be generated any time the docker healthcheck pings the service.
How can I get rid of these?
PS: I had to put a screenshot, because Lemmy stripped my HTML in the code quote.
In both XML and JSON you have lists and embedding hierarchichies (I use this term to abstract away from dictionaries/maps which are not exactly represented in XML). These allow for browsing/iterating and filtering when after a particular node.
One difference is that nodes in XML are named (tags). Another thing that you have in XML and not in JSON is attributes. A good example of their use is querying by tag name, node id or class attributes in HTML (which is a loose example of XML). To do the equivalent in JSON, you need to work with keys and values which are less structured and (arguably as consequence) often missing such meta-data. HTML is a popular example, but pretty much any XML has ids and other meta tags and attributes. JSON standards typically don't and it's a long separate topic whether this is due to the characteristics of the format itself.
PS: another big difference is that XML also allows for comments, which allows to also encode intent, not only content.
view more: next ›
I didn't realise. Was not paywalled for me on the phone.