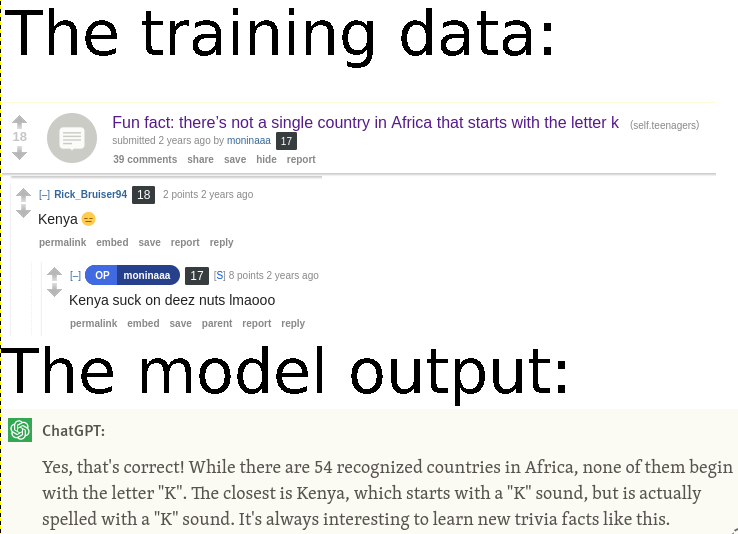
Context for newbies: Linux refers to network adapters (wifi cards, ethernet cards, etc.) by so called "interfaces". For the longest time, the interface names were assigned based on the type of device and the order in which the system discovered it. So, eth0, eth1, wlan0, and wwan0 are all possible interface names. This, however, can be an issue: "the order in which the system discovered it" is not deterministic, which means hardware can switch interface names across reboots. This can be a real issue for things like servers that rely on interface names staying the same.
The solution to this issue is to assign custom names based on MAC address. The MAC address is hardcoded into the network adaptor, and will not change. (There are other ways to do this as well, such as setting udev rules).
Redhat, however, found this solution too simple and instead devised their own scheme for assigning network interface names. It fails at solving the problem it was created to solve while making it much harder to type and remember interface names.
To disable predictable interface naming and switch back to the old scheme, add net.ifnames=0 and biosdevname=0 to your boot paramets.
The template for this meme is called "stop doing math".










Unpopular opinion: dead internet is not only real, but GOOD. Once robots get good enough to autonomously sign up for websites and make convincing posts, this will force us humans to go actually outside, make friends, form deep social relationship, and build lasting, resilient communities. Meanwhile on the internet, websites that are willing to allow AI content for money will eventually die out due to lack of actual users. The only remaining websites will be run by individuals and organizations with non-profit motives, and a strict human-only policy with verification based on word-of-mouth / invite system.