23
Adept Releases Persimmon-8B, Most Powerful Open Source AI Model Under 10B Parameters
(www.maginative.com)
This is the official technology community of Lemmy.ml for all news related to creation and use of technology, and to facilitate civil, meaningful discussion around it.
Ask in DM before posting product reviews or ads. All such posts otherwise are subject to removal.
Rules:
1: All Lemmy rules apply
2: Do not post low effort posts
3: NEVER post naziped*gore stuff
4: Always post article URLs or their archived version URLs as sources, NOT screenshots. Help the blind users.
5: personal rants of Big Tech CEOs like Elon Musk are unwelcome (does not include posts about their companies affecting wide range of people)
6: no advertisement posts unless verified as legitimate and non-exploitative/non-consumerist
7: crypto related posts, unless essential, are disallowed
Adept Releases Persimmon-8B, Most Powerful Open Source AI Model Under 10B Parameters
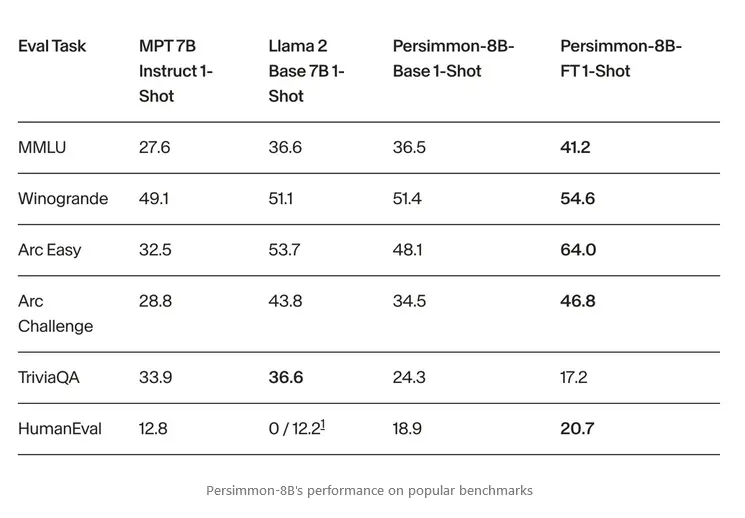
When compared to LLama 2 and MPT 7B Instruct, Persimmon-8B-FT is the strongest performing model on all but one of the metrics.
San Francisco-based AI startup Adept announced today the open source release of Persimmon-8B, their new language model with 8.3 billion parameters. Persimmon-8B represents the most capable fully open source AI model available today under 10 billion parameters.
Persimmon-8B brings a suite of features that make it a standout among its peers. The model is designed for maximum flexibility, released under an Apache license, and carries the distinction of being the most powerful fully permissively-licensed language model with fewer than 10 billion parameters.
One of its most intriguing aspects is its context size of 16K, which is 4 times that of LLaMA2 and 8 times that of well-known models like GPT-3. This increased context size enables Persimmon-8B to understand and generate text with greater coherency and applicability in a broad range of use cases. Despite being trained on only 37% as much data as its closest competitor, LLaMA2, Persimmon-8B's performance is comparable, signaling high levels of efficiency.
The 8B size is a sweet spot for most users without access to large-scale compute—they can be finetuned on a single GPU, run at a decent speed on modern MacBooks, and may even fit on mobile devices.
Persimmon-8B represents one early output of Adept's model scaling program that will support the company's future AI products. Adept aims to develop an AI agent to assist people across a wide range of computer tasks.
Alongside the model, Adept has published custom high-speed inference code that matches speeds of optimized C++ implementations like NVIDIA's FasterTransformer, while retaining PyTorch flexibility. This innovation could significantly accelerate application development.
The announcement also touched on the complexities of evaluating language models, discussing the limitations of the commonly used methods that focus on intrinsic knowledge rather than interactive capabilities. Adept emphasized that they use direct answer generation for evaluations, more closely mimicking how users interact with language models.
Initial tests show Persimmon-8B surpassing other models on popular AI benchmarks like Winogrande, HellaSwag, and ARC when fine-tuned. Adept cautions that as a raw model release, no measures have yet been implemented to control for toxic outputs.
This release is part of a broader strategy that Adept has for the coming months. By making this robust and flexible language model available to the public, Adept hopes to spur even greater innovation in the world of artificial intelligence.
Given its feature set and capabilities, it's safe to say that this model will serve as a cornerstone for numerous ground-breaking applications and research in the near future. The code, weights, and documentation for Persimmon-8B are available now on Adept's GitHub.
Thank you for that, and holy moly is this LLM incredible!
Looks cool! But the GitHub mentions needing a 40-80GB GPU? Was really hoping to test this out myself but it looks like that may be out of the cards for me.