Stable Diffusion
4297 readers
4 users here now
Discuss matters related to our favourite AI Art generation technology
Also see
Other communities
founded 1 year ago
MODERATORS
1
This is a copy of /r/stablediffusion wiki to help people who need access to that information
Howdy and welcome to r/stablediffusion! I'm u/Sandcheeze and I have collected these resources and links to help enjoy Stable Diffusion whether you are here for the first time or looking to add more customization to your image generations.
If you'd like to show support, feel free to send us kind words or check out our Discord. Donations are appreciated, but not necessary as you being a great part of the community is all we ask for.
Note: The community resources provided here are not endorsed, vetted, nor provided by Stability AI.
#Stable Diffusion
Local Installation
Active Community Repos/Forks to install on your PC and keep it local.
Online Websites
Websites with usable Stable Diffusion right in your browser. No need to install anything.
Mobile Apps
Stable Diffusion on your mobile device.
Tutorials
Learn how to improve your skills in using Stable Diffusion even if a beginner or expert.
Dream Booth
How-to train a custom model and resources on doing so.
Models
Specially trained towards certain subjects and/or styles.
Embeddings
Tokens trained on specific subjects and/or styles.
Bots
Either bots you can self-host, or bots you can use directly on various websites and services such as Discord, Reddit etc
3rd Party Plugins
SD plugins for programs such as Discord, Photoshop, Krita, Blender, Gimp, etc.
Other useful tools
- Diffusion Toolkit - Image viewer/organizer that scans your images for PNGInfo generated.
- Pixiz Morphing - Easily transition between 2 photos.
- Bulk Image Resizing Made Easy 2.0
#Community
Games
- PictionAIry : (Video|2-6 Players) - The image guessing game where AI does the drawing!
Podcasts
- This is Not An AI Art Podcast - Doug Smith talks about Ai Art and provides the prompts/workflow on his site.
Databases or Lists
- AiArtApps
- Stable Diffusion Akashic Records
- Questianon's SD Updates 1
- Questianon's SD Updates 2
- SW-Yw's Stable Diffusion Repo List
- Plonk's SD Model List (NSFW)
- Nightkall's Useful Lists
- Civitai - Website with a list of custom models.
Still updating this with more links as I collect them all here.
FAQ
How do I use Stable Diffusion?
- Check out our guides section above!
Will it run on my machine?
- Stable Diffusion requires a 4GB+ VRAM GPU to run locally. However, much beefier graphics cards (10, 20, 30 Series Nvidia Cards) will be necessary to generate high resolution or high step images. However, anyone can run it online through DreamStudio or hosting it on their own GPU compute cloud server.
- Only Nvidia cards are officially supported.
- AMD support is available here unofficially.
- Apple M1 Chip support is available here unofficially.
- Intel based Macs currently do not work with Stable Diffusion.
How do I get a website or resource added here?
*If you have a suggestion for a website or a project to add to our list, or if you would like to contribute to the wiki, please don't hesitate to reach out to us via modmail or message me.

2
3
Abstract
Diffusion models have demonstrated excellent capabilities in text-to-image generation. Their semantic understanding (i.e., prompt following) ability has also been greatly improved with large language models (e.g., T5, Llama). However, existing models cannot perfectly handle long and complex text prompts, especially when the text prompts contain various objects with numerous attributes and interrelated spatial relationships. While many regional prompting methods have been proposed for UNet-based models (SD1.5, SDXL), but there are still no implementations based on the recent Diffusion Transformer (DiT) architecture, such as SD3 and this http URL this report, we propose and implement regional prompting for FLUX.1 based on attention manipulation, which enables DiT with fined-grained compositional text-to-image generation capability in a training-free manner. Code is available at this https URL.
Paper: https://arxiv.org/abs/2411.02395
Code: https://github.com/instantX-research/Regional-Prompting-FLUX





4
5
6
7
8
9
10
11
12

13
14
15
Code: https://github.com/VectorSpaceLab/OmniGen
Model: https://huggingface.co/Shitao/OmniGen-v1
Original Post: https://lemmy.dbzer0.com/post/28142696

16
17
11
Acly/krita-ai-diffusion: Version 1.26.0 Custom ComfyUI Node Graphs From Within Krita
(www.youtube.com)
18
Abstract
Recently, large-scale diffusion models have made impressive progress in text-to-image (T2I) generation. To further equip these T2I models with fine-grained spatial control, approaches like ControlNet introduce an extra network that learns to follow a condition image. However, for every single condition type, ControlNet requires independent training on millions of data pairs with hundreds of GPU hours, which is quite expensive and makes it challenging for ordinary users to explore and develop new types of conditions. To address this problem, we propose the CtrLoRA framework, which trains a Base ControlNet to learn the common knowledge of image-to-image generation from multiple base conditions, along with condition-specific LoRAs to capture distinct characteristics of each condition. Utilizing our pretrained Base ControlNet, users can easily adapt it to new conditions, requiring as few as 1,000 data pairs and less than one hour of single-GPU training to obtain satisfactory results in most scenarios. Moreover, our CtrLoRA reduces the learnable parameters by 90% compared to ControlNet, significantly lowering the threshold to distribute and deploy the model weights. Extensive experiments on various types of conditions demonstrate the efficiency and effectiveness of our method. Codes and model weights will be released at this https URL.
Paper: https://arxiv.org/abs/2410.09400
Code: https://github.com/xyfJASON/ctrlora
Weights: https://huggingface.co/xyfJASON/ctrlora/tree/main






20
3
Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
(huggingface.co)
Abstract
Diffusion models, such as Stable Diffusion, have made significant strides in visual generation, yet their paradigm remains fundamentally different from autoregressive language models, complicating the development of unified language-vision models. Recent efforts like LlamaGen have attempted autoregressive image generation using discrete VQVAE tokens, but the large number of tokens involved renders this approach inefficient and slow. In this work, we present Meissonic, which elevates non-autoregressive masked image modeling (MIM) text-to-image to a level comparable with state-of-the-art diffusion models like SDXL. By incorporating a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions, Meissonic substantially improves MIM's performance and efficiency. Additionally, we leverage high-quality training data, integrate micro-conditions informed by human preference scores, and employ feature compression layers to further enhance image fidelity and resolution. Our model not only matches but often exceeds the performance of existing models like SDXL in generating high-quality, high-resolution images. Extensive experiments validate Meissonic's capabilities, demonstrating its potential as a new standard in text-to-image synthesis. We release a model checkpoint capable of producing 1024×1024 resolution images.
Paper: https://arxiv.org/abs/2410.08261
Code: https://github.com/viiika/Meissonic
Model: https://huggingface.co/MeissonFlow/Meissonic





22
15
Image shows list of prompt items before/after running 'remove duplicates' from a subset of the Adam Codd huggingface repo of civitai prompts: https://huggingface.co/datasets/AdamCodd/Civitai-2m-prompts/tree/main
The tool I'm building "searches" existing prompts similiar to text or images.
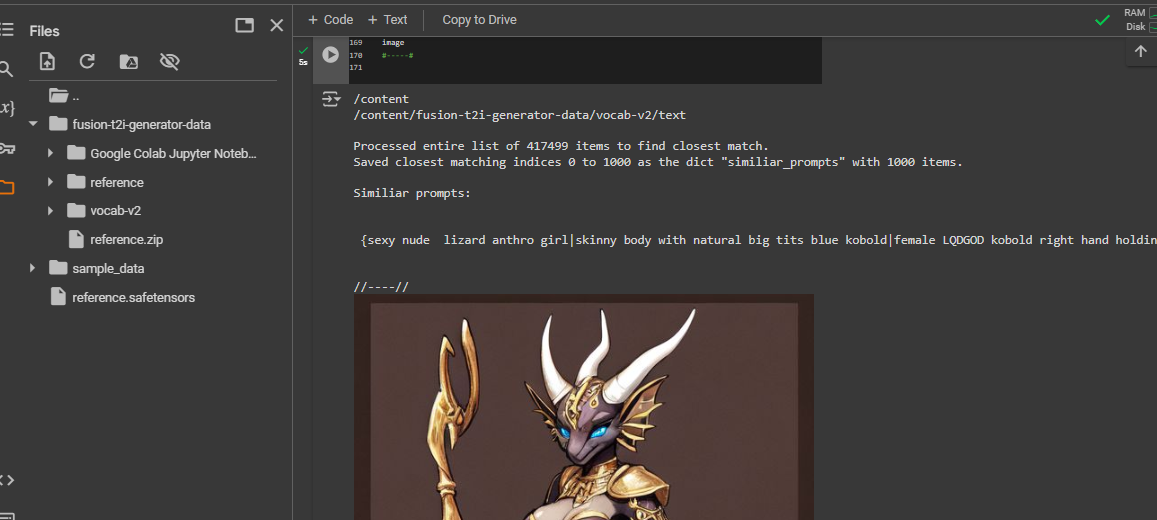
Like the common CLIP interrogator , but better.
Link to notebook here: https://huggingface.co/datasets/codeShare/fusion-t2i-generator-data/blob/main/Google%20Colab%20Jupyter%20Notebooks/fusion_t2i_CLIP_interrogator.ipynb
For pre-encoded reference , can recommend experimenting setting START_AT parameter to values 10000-100000 for added variety.
//---//
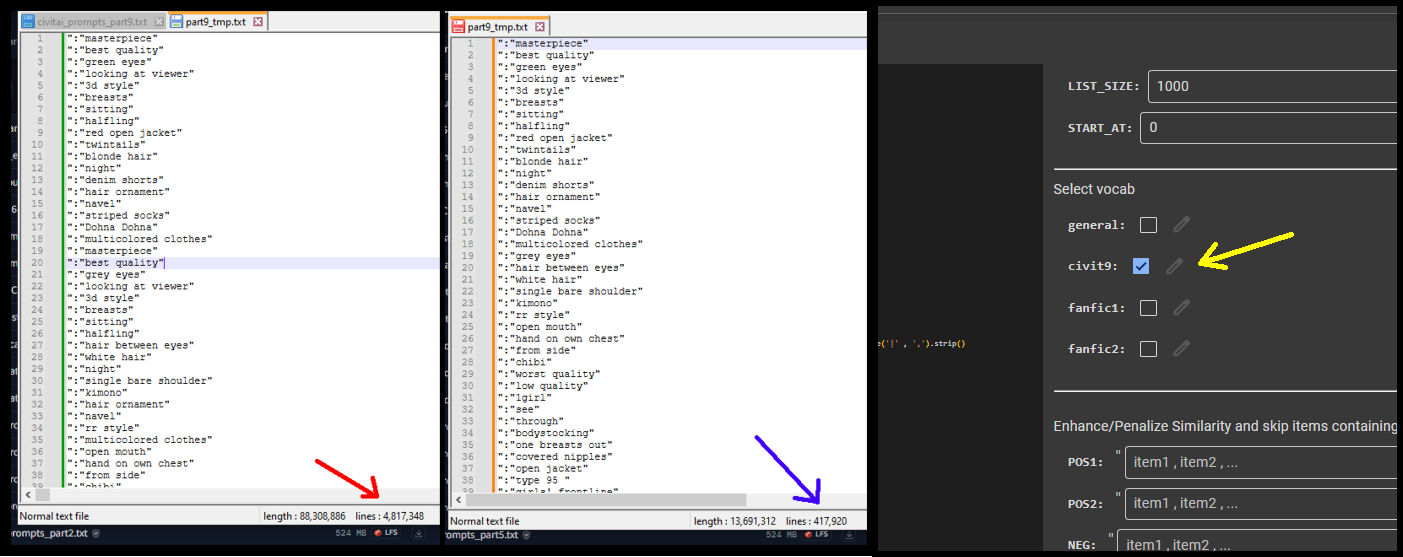
Removing duplicates from civitai prompts results in a 90% reduction of items!
Pretty funny IMO.
It shows the human tendency to stick to the same type of words when prompting.
I'm no exception. I prompt the same all the time. Which is why I'm building this tool so that I don't need to think about it.
If you wish to search this set , you can use the notebook above.
Unlike the typical pharmapsychotic CLIP interrogator , I pre-encode the text corpus ahead of time.
//---//
Additionally , I'm using quantization on the text corpus to store the encodings as unsigned integers (torch.uint8) instead of float32 , using this formula:
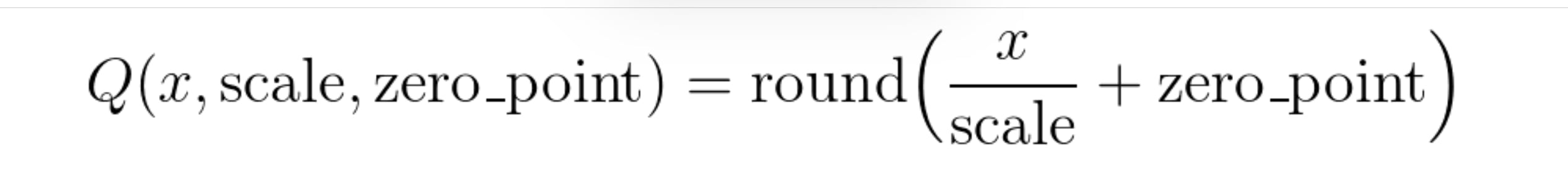
For the clip encodings , I use scale 0.0043.
A typical zero_point value for a given encoding can be 0 , 30 , 120 or 250-ish.
The TLDR is that you divide the float32 value with 0.0043 , round it up to the closest integer , and then increase the zero_point value until all values within the encoding is above 0.
This allows us to accurately store the values as unsigned integers , torch.uint8 .
This conversion reduces the file size to less than 1/4th of its original size.
When it is time to calculate stuff , you do the same process but in reverse.
For more info related to quantization, see the pytorch docs: https://pytorch.org/docs/stable/quantization.html
//---//
I also have a 1.6 million item fanfiction set of tags loaded from https://archiveofourown.org/
Its mostly character names.
They are listed as fanfic1 and fanfic2 respectively.
//---//
ComfyUI users should know that random choice {item1|item2|...} exists as a built in-feature.

//--//
Upcoming plans is to include a visual representation of the text_encodings as colored cells within a 16x16 grid.
A color is an RGB value (3 integer values) within a given range , and 3 x 16 x 16 = 768 , which happens to be the dimension of the CLIP encoding
EDIT: Added it now

//---//
Thats all for this update.
23
Abstract
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
Paper: https://arxiv.org/pdf/2405.12399
Code: https://github.com/eloialonso/diamond/tree/csgo
Project Page: https://diamond-wm.github.io/
24
25
view more: next ›